The algorithm starts out with rules that have first order conditions, i.e.
![]() consists only of one (variable, value)-pair (
consists only of one (variable, value)-pair (
![]() ).
It finds K rules, calculates their J-measures, and places these rules in an ordered list.
The smallest J-measure defines the ``running minimum Jmin''.
Then the J-measure of new solution-set candidates is compared
with Jmin. Better rules are inserted and Jmin is updated.
Before continuing the evaluation of first-order rules, it is decided for each rule
whether further specialization, meaning adding (variable, value)-pairs
to the precondition, is worthwhile.
).
It finds K rules, calculates their J-measures, and places these rules in an ordered list.
The smallest J-measure defines the ``running minimum Jmin''.
Then the J-measure of new solution-set candidates is compared
with Jmin. Better rules are inserted and Jmin is updated.
Before continuing the evaluation of first-order rules, it is decided for each rule
whether further specialization, meaning adding (variable, value)-pairs
to the precondition, is worthwhile.
In particular, we can calculate an upper bound
for the information content of a specialization
(see [41] for derivation) :
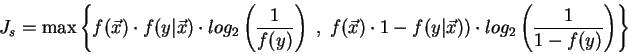
The problem of this algorithm is its computational complexity.
Let
![]() be the dimensions of the overall relation. Denote
ki := |dom(di)|,
be the dimensions of the overall relation. Denote
ki := |dom(di)|,
![]() as the number of values in the domain of
variable di. Then
as the number of values in the domain of
variable di. Then
![]() is the number of rule conclusions,
k2 is the approximate number of first-order rules (2k2 if we
separate transition probabilities close to 1 and 0). For all these rules
rules J-measures and bounds need to be computed, which can be many if
the database is wide and therefore k large. Furthermore a much greater number
of specializations of these rules need to be evaluated.
We presume that this together is in the order of O(kn).
is the number of rule conclusions,
k2 is the approximate number of first-order rules (2k2 if we
separate transition probabilities close to 1 and 0). For all these rules
rules J-measures and bounds need to be computed, which can be many if
the database is wide and therefore k large. Furthermore a much greater number
of specializations of these rules need to be evaluated.
We presume that this together is in the order of O(kn).
The use of value hierarchies (Coarsening, Refinement) is an important feature and needs to be considered in further implementations of this algorithm, so far hierarchies are not supported.
A number of other variations are considerable for this algorithm. Instead of specifying the number K the user could define a minimum information content Jmin. Other constraints on variables and values could be user-defined. See also the paragraph `Discussion' for using rule inference in a user-guided manner.