


Next: Discussion:
Up: Rule inference
Previous: ITRULE Algorithm:
The similar problem of finding ``association rules'' was introduced by Agrawal, et.al., 1993
[4] in the context of market-basket research (section 3.3).
In this field the buying behavior of customers is the main interest; we want to investigate
what subsets of items are usually bought together in one ``transaction''.
Therefore association rules usually operate on sets of items, but by seeing one
(variable, value)-pair as one item and one database-record as a transaction
we can transfer our problem to this methodology.
Note that by doing so some restrictions are imposed on the transactions:
each transaction has the same number of items, that is exactly one for each variable;
items with different values for the same variable are
excluded from being in the same transaction.
An association rule is defined as an expression:
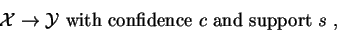 |
(30) |
where
is the set of all items and
are subsets of items.
The interpretation of an association rule is that ``transactions in the
database which contain the items in
 also tend
to contain the items in
also tend
to contain the items in
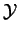 '' [47].
The data
'' [47].
The data
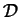 to be investigated consists of a set of Transactions
T, which are themselves subsets of items, i.e. all the items a customer
bought at the same time:
to be investigated consists of a set of Transactions
T, which are themselves subsets of items, i.e. all the items a customer
bought at the same time:
As already described there are two
basic measures for evaluating the strength of an association rule.
The ``confidence'' c) measures the percentage of transactions in which
the items
were bought whenever the items in
were bought (frepresents the induced frequency distribution from the data
):
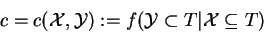 |
(31) |
The ``support'' (s) expresses the significance of the rule as the percentage of all
transactions which contain both the items in
and
:
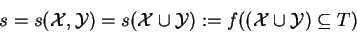 |
(32) |
The problem of mining association rules
is to find all rules that satisfy a user-specified minimum support and confidence.
It is decomposed into 3 parts [47]:
- 1.
- Find all sets of items
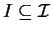 (``frequent itemsets'')
which are subset of more transaction Ti than the user-defined minimum.
In other words find all subsets of
which
satisfy a specified minimum support.
This can be done in a simple
cumulative algorithm because of the nestedness of the subset property:
If an itemset I fullfills the requirement, so do all subsets of I.
By starting with single items and sequentially joining itemsets while
checking for minimum support we are able to efficiently determine the
frequent itemsets. In this procedure we also automatically obtain
the support for all frequent itemsets including their subsets (which are also
frequent itemsets). This is used in the next step.
(``frequent itemsets'')
which are subset of more transaction Ti than the user-defined minimum.
In other words find all subsets of
which
satisfy a specified minimum support.
This can be done in a simple
cumulative algorithm because of the nestedness of the subset property:
If an itemset I fullfills the requirement, so do all subsets of I.
By starting with single items and sequentially joining itemsets while
checking for minimum support we are able to efficiently determine the
frequent itemsets. In this procedure we also automatically obtain
the support for all frequent itemsets including their subsets (which are also
frequent itemsets). This is used in the next step.
- 2.
- Use the frequent itemsets to generate desired rules. The general idea is
that if
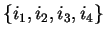 is a frequent itemset, then we can
determine the confidence for a rule
is a frequent itemset, then we can
determine the confidence for a rule
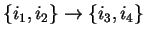 by computing
by computing
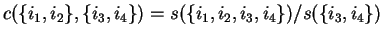 .
.
- 3.
- Prune all uninteresting rules from this set. The criteria for ``interesting''
must be defined according to the Purpose of Investigation.
Using this concept several fast algorithms have been developed.
For more details and references see one of the
many papers on association rules [4,47,36] etc.
As mentioned earlier, hierarchies of values, or in this case hierarchies defined on
the itemsets, are important for finding general pattern. This is especially true
for this case as we preselect rules according to their support.
The name for using hierarchies (taxonomies) in market-basket-research is
``Generalized Association Rules''; appropriate
algorithms have been developed [47].
The confidence and support measures are fairly elementary and not necessarily
sufficient in describing interesting rules. Other measures based on statistics,
i.e. chi-square test, have been proposed [36].
Next: Discussion:
Up: Rule inference
Previous: ITRULE Algorithm:
Thomas Prang
1998-06-07