Reconstructability Analysis is similar to Analysis of Variance (section 3.3.1) in its approach of finding structure within a wide relation. Both methods try to identify the strength of relationships and correlations among variables. While ANOVA assumes a model of interaction effects which are then estimated via statistical inference, RA does not assume an interaction model; instead it starts with an interaction hypothesis about which variables and not how they are connected.
To estimate the interaction-effects via RA, e.g. ABCijk,
one reconstruction hypothesis connecting all these values, e.g.
![]() and one which only contains proper subsets of them,
e.g.
and one which only contains proper subsets of them,
e.g.
![]() ,
is computed.
Then comparing the probabilities in both unbiased reconstructions we are able to
estimate the interaction effect, e.g. ABCijk, as the difference in those
probabilities.
Jones suggests that K-systems should be prefered to ANOVA in many instances.
For a more detailed discussion of the comparison between ANOVA and RA see
[21,22].
``We conclude that there are significant differences between statistical and
K-systems (RA) interactions, and that these differences are due to the erroneous
model and simplifying assumptions of statistical interaction [in ANOVA].''
[22, pg. 169].
,
is computed.
Then comparing the probabilities in both unbiased reconstructions we are able to
estimate the interaction effect, e.g. ABCijk, as the difference in those
probabilities.
Jones suggests that K-systems should be prefered to ANOVA in many instances.
For a more detailed discussion of the comparison between ANOVA and RA see
[21,22].
``We conclude that there are significant differences between statistical and
K-systems (RA) interactions, and that these differences are due to the erroneous
model and simplifying assumptions of statistical interaction [in ANOVA].''
[22, pg. 169].
Comparing RA with the basic techniques we recognize that basically projection and extension are used. The data is projected into our models and then extended via unbiased join procedures. By searching through model space we look for good models which contain the identified additional structure in their refined subrelations; some variables are linked more directly than in the overall relation, other variables are disconnected altogether.
Another use of reconstructability analysis has been suggested by Klir in 1981
[25]. The ``reconstruction principle of
inductive inference'' expresses that the reconstruction system derived from sampled
data is usually a better estimate to the true distribution than the sampled data
itself.
This hypothesis is supported by several experiments
[25,14,38] and can be explained as follows:
The relative sample-size over the domain is larger for any of the projections
![]() than for the whole domain:
than for the whole domain:
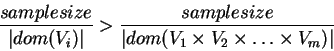
If the overall system is approximately reconstructable from our model, then we can obtain a better approximation of the true distribution by using this model. However, as there are already many other methods for improving probability estimates (contingency table analysis, etc.) Pitarelli concludes ``(Reconstructability analysis) is neither the only nor necessarily the best technique for improving an initial relative frequency estimate of a probability distribution defined over a finite product space.'' [38, pg. 20].