Fisher's method [10], [20, pp. 470] is a supervised method for the classification-problem into two classes by using the knowledge of some continuous input-variables. It corresponds to the historic Neural Network ``Perceptron'' [37] (also known as ``Linear Machine'') but uses a different approach for ``learning'' the model.
Let
![]() be the known continuous p input-variables,
and Y the classification variable with two states.
Fisher's method assumes that the conditional Probability distributions
are normally distributed with the same (invertible) covariance
matrix:
be the known continuous p input-variables,
and Y the classification variable with two states.
Fisher's method assumes that the conditional Probability distributions
are normally distributed with the same (invertible) covariance
matrix:
The normal distribution assumption guaranties optimal fit of the model, but is not necessary, whereas the assumption of same covariance matrices can be critical for Fisher's model calculation.
Now the aim of the method is to find a linear combination of the variables
Xi which is best able to discriminate the two classes of Y.
Formally, we are are looking for a vector l:
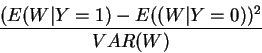
This vector l defines the best linear combination of the Xi variables for the
scalar (univariate) random
variable W to discriminate between the two classes (the difference between
the conditional expected values are maximal with respect to its variance).
The expected values and variance are:
For classifying a new observation
![]() we just
multiply it with lto calculate its linear combination (the value of the random variable W).
Then we classify according to this value.
If it's closer to the mean
we just
multiply it with lto calculate its linear combination (the value of the random variable W).
Then we classify according to this value.
If it's closer to the mean ![]() then we classify it as class 0, otherwise as class 1.
Let
then we classify it as class 0, otherwise as class 1.
Let
![]() ,
and assume
,
and assume
![]() ,
then
the classificiation for x* is:
,
then
the classificiation for x* is:
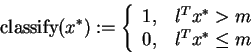 |
(13) |
The remaining question is how to train the model, how to obtain the vector l. Here Fisher's Method and the Perceptron differ in their approaches.
If both populations
![]() and
and
![]() have the same covariance-matrix
have the same covariance-matrix
![]() ,
then:
,
then:
| (14) |
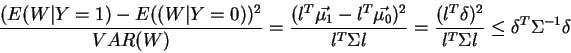
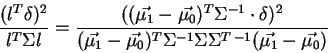
Fisher's Method uses this result to derive the statistically
``optimal'' model.
The Covariance-matrix ![]() and the means
and the means
![]() and
and
![]() are obtained via unbiased estimators
[20, pp. 474].
In this case the random variable W is also known as
``Fisher's Sample Linear Discrimination Function''.
are obtained via unbiased estimators
[20, pp. 474].
In this case the random variable W is also known as
``Fisher's Sample Linear Discrimination Function''.
While Fisher's Method is grounded on statistical inference the
Perceptron doesn't make any assumptions about the distributions.
The Perceptron with initial random weights (the vector l) is
sequentially given training data for classification. Whenever
the classification is wrong l is adjusted by adding or subtracting
(depending on the right classification) a learning-parameter ![]() times the input vector.
It is known that
the ``weight-vector'' l of the Perceptron will converge [37].
times the input vector.
It is known that
the ``weight-vector'' l of the Perceptron will converge [37].
How do these methods relate to the presented basic structure-finding techniques? First of all they require continuous variables and don't work with nominal data. But as they are famous historical methods I wanted to present them for completeness and for understanding of the structure-finding problem. They also state good examples for using the technique of creating new dimensions.
In this case the new dimension is computed by a linear combination of
the other dimensions. The aim is to select this dimension according to the
model such that the conditional distributions
![]() and
and
![]() are as
different as possible.
Using these linear methods means that we are looking for an n-1 dimensional hyperplane in
the n-dimensional variable-space for separating our 2 classes;
we are looking for one new dimension which then can be used projected and conditionalized
for classifying new unknown data entities.
are as
different as possible.
Using these linear methods means that we are looking for an n-1 dimensional hyperplane in
the n-dimensional variable-space for separating our 2 classes;
we are looking for one new dimension which then can be used projected and conditionalized
for classifying new unknown data entities.