![]()
![]()
![]()
![]()
enqueue(s,x);
WHILE NOT emptyqueue(s) DO
u := front(s); dequeue(s);
FOREACH Nachbar v von u DO
tmp := d[u] + c[u,v];
IF tmp < d[v] THEN
d[v] := tmp;
IF v ist nicht in Schlange s
THEN enqueue (s,v)
END
END
END
END
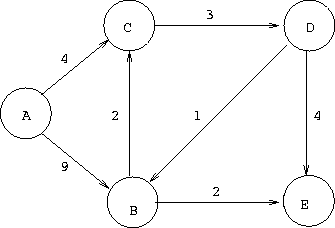
| A | B | C | D | E | Schlange | |
| 0 | |
|
|
|
A | |
| 0 | 9 | 4 | |
|
BC | |
| 0 | 9 | 4 | |
11 | CE | |
| 0 | 9 | 4 | 7 | 11 | ED | |
| 0 | 9 | 4 | 7 | 11 | D | |
| 0 | 8 | 4 | 7 | 11 | BE | |
| 0 | 8 | 4 | 7 | 10 | E | |
| 0 | 8 | 4 | 7 | 10 |
| Ablauf des Moore-Algorithmus | |
| mit Graph, Distanzvektor, Schlange und | |
| Startknoten A. |
Parallele Version des Moore -Algorithmus für p Prozessoren, shared memory
enqueue (Q,x);
WHILE NOT emptyqueue (Q) DO
FOR ALL
0 ![]() i
i ![]() p - 1 DO IN PARALLEL
p - 1 DO IN PARALLEL
Pi :
hole Menge von Knoten
Q i aus der Schlange Q
und bearbeite jedes Element aus
Q i einmal
Ergebnis ist Schlange
Q 'i
Gliedere
Q 'i in Q ein
END
END
Menge Q ist gespeichert in
VAR Q : ARRAY [0..max-1] OF INTEGER;Q[i] > 0 => Q[i] ist Knotenname

Prozessor i bildet sein Qi , indem er, beginnend bei Position i ,
jedes p -te Arrayelement aufsammelt
(dabei bei negativen Einträgen dem Zeiger folgt).
Qi' wird, beginnend bei Position si , hintereinander
abgespeichert in Q .
Hinter dem letzten Knoten von Q'i folgen p
Verweise auf die ersten p Elemente der Menge Q'i + 1 .
Jeder Prozessor hat dieselbe Anzahl ( ![]() 1 )
von Knoten zu bearbeiten.
1 )
von Knoten zu bearbeiten.
Obacht:
VAR d: ARRAY [0..n-1] OF INTEGER (* vorläufige Distanzen *)
VAR inqueue: ARRAY [0..n-1] OF BOOLEAN (* Knoten in Schlange *)
sind global zugreifbar.
Hierdurch entsteht ein Synchronisationsproblem.
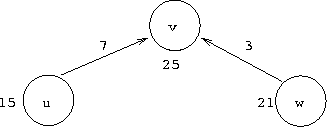
| Synchronisationsproblem zwischen 2 Prozessoren, | |
| die die Kanten (u,v) bzw. (w,v) bearbeiten. |
tmp = d[u] + c[u,v] = 22 => d[v] := 22
tmp = d[w] + c[w,v] = 24 => d[v] := 24
Das Update von v auf 22 geht verloren.
| Also: | lock d[v]; |
| tmp := d[u] + c [u,v]; | |
| IF tmp < d[v] THEN d[v] := tmp END; | |
| unlock d[v]; | |
| Analog: | lock in_queue[x]; ... |
| unlock in_queue[x]; |