![]()
![]()
![]()
![]()
Die kleinste lautsprachliche Einheit nennt man Phonem. Im Deutschen gibt es etwa 40 Phoneme (Konsonanten, kurze und lange Vokale und Diphtonge):
b, p, d, t, f, w, g, k, l, m, n, r, s, ß, sch, z, x
a:, a, e:, e, i:, i, o:, o, u:, u,
ä:, ä, ö, ö:, ü, ü:, ai, au, ui.
Die während der Artikulation eines Phonems erzeugten
Merkmalsvektoren können durch eine Wolke in
einem hochdimensionalen Raum charakterisiert werden.
Form und Lage einer Phonem-Wolke ist sprecherabhängig und
wird in einer mehrstündigen Trainingsphase ermittelt.
Aus Gründen der Rechenökonomie beschreibt man die Wolken als
Kugeln oder Ellipsoide.
Ggf. wird der zuständige Teilraum durch mehrere Standardwolken
angenähert.
Genauer: Je näher ein Merkmalsvektor dem Mittelpunkt eines Ellipsoids liegt, desto größer ist die Wahrscheinlichkeit, daß er zu dem entsprechenden Phonem gehört. Auf die Fläche des Ellipsoids fallen im Mittel 50 % der Realisierungen des entsprechenden Phonems. Ein Punkt außerhalb kann durchaus zu diesem Phonem gehören, aber es ist recht unwahrscheinlich.
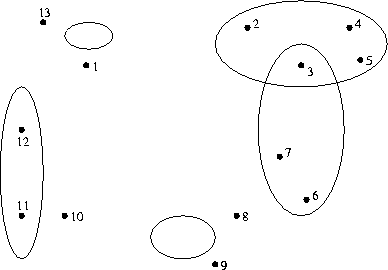
13 Merkmalsvektoren und ihre Beziehung zu 5 Phonem-Wolken