| Vorlesung | Übungsaufgabe | gestellt am |
| Thümmel: Formale Syntax | Vereinigung von L1 und L2 | 15. Jan. 1998 |
| Sprache | Regeln der Syntax | Syntax Typ |
| Vereinigung von L1 und L2:
{ x | x = a b* a oder x Î {a, b}* mit genau zwei b} |
S -> A
S -> B A -> aCa C -> e C -> bC B -> aB B -> bD D -> aD D -> bE E -> aE E -> e |
Typ 1nr |
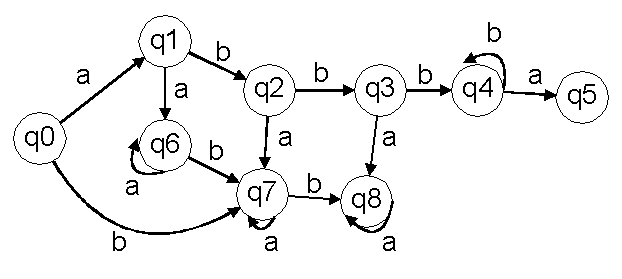
| K | {q0, q1, q2, q3, q4, q5, q6, q7, q8} | Zustände |
| V | {a, b} | Eingabesymbole |
| S | {q0} | Startzustände |
| F | {q5, q8} | Endzustände |
| d | (q0, a) -> (q1)
(q1, b) -> (q2) (q2, b) -> (q3) (q3, b) -> (q4) (q4, b) -> (q4) (q4, a) -> (q5) (q0, b) -> (q7)
(q6, a) -> (q6)
(q1, a) -> (q6)
|
Übergangsfunktion |
| L1 | { x = ab*a } | S -> aBa
B -> e B -> bB |
Typ 1nr |
| L2 | { x Î {a, b}* | b in x genau zwei mal enthalten} | S -> aS
S -> Sa S -> bB S -> Bb B -> aB B -> Ba B -> bC B -> Cb C -> aC C -> e |
Typ 0 |
| L2 | { x Î {a, b}* | b in x genau zwei mal enthalten} | S -> aS
S -> bB B -> aB B -> bC C -> aC C -> e |
Typ 0, da S Î y
(sonst Typ 3 kontextfrei, rechtslinear und rechtsprädikativ) |
| L2 | { x Î {a, b}* | b in x genau zwei mal enthalten} | S -> AbAbA
A -> e A -> aA |
| Sprache | Regeln der Syntax | Syntax Typ |
| Vereinigung von L1 und L2:
{ x | x = a b* a oder x Î {a, b}* mit genau zwei b} |
S -> A
S -> B A -> aCa C -> e C -> bC B -> DbDbD D -> e D -> aD |
Typ 1nr |