


Next: Algorithm and Decision Tree
Up: Decision Trees
Previous: Decision tree building:
How are rules selected for each node? The most famous approach used in ID3
[45] is called ``information gain'', and is based on Shannon's entropy.
``Variants of the information gain (...) have become the de facto standard metrics
for TDIDT split selection'' [32, pg. 263].
Let C be the classification variable,
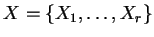 a set of variables
with nominal or discretized values. The variable set X is to be evaluated as
a node condition in separating the classification classes
a set of variables
with nominal or discretized values. The variable set X is to be evaluated as
a node condition in separating the classification classes 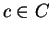 .
The information gain GC(X) is then defined as:
.
The information gain GC(X) is then defined as:
|
GC(X) := H(C) - H(C|X)
|
(33) |
From section 2.2 we know that the information gain is 0 if variables C
and X are independent (
H(C) = H(C|X)). The more they are ``correlated'' the
lower is the predictive uncertainty H(C|X) and the higher the information gain.
Several variation of this measure are known [32]. One of them
is called ``gain ratio'' and tries to compensate the known bias of gain towards
variable sets with larger domains (more values):
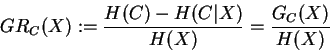 |
(34) |
Other measures include the Chi-square statistics, Fisher's exact test,
category utility measure, etc. [32].
The important point in selecting rules for decision nodes is that we
want to maximize class homogeneity within partitions and maximize
classndistance between partitions.
Next: Algorithm and Decision Tree
Up: Decision Trees
Previous: Decision tree building:
Thomas Prang
1998-06-07