Ein Teil der Aufgabenstellung der vorliegenden Diplomarbeit ist die ,,Visualisierung von raum- und zeitbezogenen Daten mit Macromedia Flash``. Damit ist Flash als das Ausgabeformat des Visualisierungsprozesses vorgegeben, nicht jedoch das oder die Formate der Eingabedaten.
Eine breite Unterstützung möglicher Eingabeformate kann im Rahmen dieser Arbeit nicht realisiert werden. Ebensowenig darf eine Beschränkung auf das Datenformat der beispielhaft verwendeten Wettervorhersagedaten erfolgen. Die Idee ist vielmehr, eine Schnittstelle zwischen Eingabedaten und Visualisierungsmodul zu definieren, dessen Format sehr genau die Fähigkeiten von Macromedia Flash widerspiegelt. Im Gegensatz zum bitcodierten SWF-Dateiformat soll dieses Zwischenformat jedoch leicht zu lesen und zu bearbeiten sein, damit beliebige Eingabedaten relativ einfach dorthin konvertiert werden können. Das angestrebte Schnittstellenformat muss die Flash-Dateistruktur bestehend aus Tags und Records abbilden und ebenfalls erweiterbar sein. Ein textbasiertes Format bietet sich an, das einen Wortschatz definiert, mit dessen Hilfe die Struktur eines Flash-Filmes beschrieben werden kann. Der Flash-Generator aus Abbildung 2.4 liest eine solche Textdatei, die notfalls mit einem Texteditor erstellt werden kann, und erzeugt ohne weitere Programmierung aus dem Inhalt den beschriebenen Flash-Film. Da der Flash-Generator auf dem SWF Software Development Kit basiert (siehe Abschnitt 2.4), erweist sich eine direkte Abbildung der SDK-Klassen durch das Schnittstellenformat als noch eleganter: Die vom Flash-Generator eingelesene Information kann direkt in Objekte des SWF-SDK umgesetzt werden.
Abbildung 3.1 zeigt einen erweiterten Entwurf des Visualisierungsprozesses.
Ein erster Ansatz, ein Zwischenformat nach den oben genannten Anforderungen zu entwickeln, ließ ein Schnittstellenformat mit eigener Syntax entstehen. Lese- und Schreibmodule für dieses Format hätten ebenso wie Klassen zur Manipulation der Daten implementiert werden müssen. Ein Standard, der gewisse Grundregeln vorschreibt, wie strukturierte Daten in einer Textdatei abzulegen sind, ist XML. Was XML bedeutet, welche Ideen mit diesem Standard verfolgt werden und warum die Implementation eigener Schreib- und Lesemodule nicht mehr erforderlich ist, beschreiben die folgenden Abschnitte.
XML ist eine Abkürzung und steht für eXtensible Markup Language. Eine Kurzdefinition lautet: ,,XML ist eine textbasierte Meta-Auszeichnungssprache, die die Beschreibung, den Austausch, die Darstellung und die Manipulation von strukturierten Daten erlaubt, so dass diese - vor allem über das Internet - von einer Vielzahl von Anwendungen genutzt werden können.`` [ZAIT2000]
Eine Auszeichnungssprache formatiert Texte mit Hilfe von Auszeichnungen (oder Markierungen, engl. Markup), die den Inhalt des Dokuments in einzelne Elemente strukturieren. Diese Auszeichnungen sind selbst im Textformat gehalten und heißen im allgemeinen Sprachgebrauch Tags. Sie bestehen aus einer Start- und einer Endmarke und bilden zusammen mit dem jeweils markierten Inhalt die Elemente des Dokuments. Die inhaltliche Bedeutung oder visuelle Formatierung eines Elements bestimmt der Name des Tags. Komplexere Dokumentstrukturen entstehen durch die Schachtelung von Elementen.
,,Extensible`` heißt XML, da es sich im Gegensatz zu HTML nicht um ein festes Format im Sinne einer bestimmten Auszeichnungssprache, sondern um eine Metasprache handelt. Eine Metasprache ist eine Sprache zur Beschreibung von Sprachen, d.h. sie stellt Vorschriften bereit, um eine beliebige Anzahl konkreter Auszeichnungssprachen für die verschiedensten Arten von Dokumenten zu definieren. XML liefert ein Konzept, wie Daten zu strukturieren sind, ohne dass vorher festgelegt wird, welche Elemente zur Verfügung stehen. Eine mittels XML definierte Sprache heißt auch XML-Anwendung oder XML-Ausprägung.
Mit XML können Struktur und Inhalt von Dokumenten so präzise beschrieben werden, dass es letztlich nicht mehr notwendig ist, die zum Verständnis und der Weiterverarbeitung von Daten notwendigen Informationen fest in die Anwendungen zu integrieren.
Mit der Hypertext Markup Language (HTML) existiert eine Auszeichnungssprache, deren Einfachheit den Siegeszug des WorldWideWeb zu Beginn und Mitte der Neunziger Jahre ermöglichte. 1989 entwickelte Tim Berners-Lee am Forschungszentrum der Europäischen Organisation für Kernforschung, CERN, diese Hypertextauszeichnungssprache mit dem primären Ziel, den Austausch wissenschaftlicher Dokumente mit der Möglichkeit des Verweisens auf entfernte Quellen zu unterstützen. HTML ist damit vornehmlich eine Präsentationsbeschreibungssprache.
Der Vorteil von HTML liegt in seiner Einfachheit: Die Sprache besteht in der Version 3.2 aus ca. 70 Tags und über 50 Attributen [Mach1997]. Doch diese Einfachheit hat auch ihren Preis. Durch den kommerziellen Erfolg des WorldWideWeb und wachsende Möglichkeiten und Anforderungen an den Datenaustausch über das Internet wurde deutlich, dass sich HTML für anspruchsvollere Anwendungen disqualifiziert. Die ursprüngliche Aufgabe der strukturierten Darstellung von Daten trat immer mehr in den Hintergrund. HTML wurde zum Medium für virtuelle Kaufhäuser, Banken und andere graphisch aufwendige Webseiten. So nutzt inzwischen eine Vielzahl von Anwendungen wie etwa Datenbanken mit HTML-Frontend das WorldWideWeb als Oberfläche. Allerdings geht durch die Verwendung von HTML die reiche, innere Struktur der Daten verloren. Komplexere Strukturen wie das Relationenschema einer Datenbank oder Objekthierarchien sind nicht abbildbar. Weiterhin ist es mit HTML nicht möglich, Daten semantisch auszuzeichnen, d.h. den Dokumenten Informationen über ihren Inhalt, jenseits der reinen Darstellung, mitzugeben. ,,Bei der Umsetzung in Web-Dokumente findet immer ein Informationsverlust statt. Bei einer über das Web abfragbaren relationalen Datenbank etwa verschwindet die auf dem Server vorhandene Strukturierung der Nutzdaten in Felder auf der Client-Seite in einem Meer von Tags. Eine Nutzung der Daten beim Betrachter, die über das Ausschneiden von Text mittels Cut & Paste hinausgeht, ist nicht mehr möglich.`` [Mach1997]
Die häufig als ,,HTML-Dilemma`` bezeichneten Defizite von HTML lassen sich wie folgt zusammenfassen [Bosa1997]:
Mit SGML (Standard Generalized Markup Language) existiert seit über zehn Jahren ein internationaler Standard (ISO 8879) für die Definition, Identifikation und Benutzung der Struktur und des Inhalts von Dokumenten. Als Metasprache stellt SGML Vorschriften bereit, um Auszeichnungssprachen formal zu definieren. SGML dient als Basis für die verschiedensten Auszeichnungssprachen auf diversen Medien. Es enthält dazu Sprachmittel für unterschiedlichste Zwecke und ist damit eine äußerst flexible Architektur, mit der Dokumente für beliebige Medien aufbereitet werden können, ohne die Struktur der Daten zu verlieren. So ist HTML eine Anwendung (genauer: ein Dokumenttyp) von SGML. Problematisch ist jedoch die Komplexität von SGML, die die Entwicklung von SGML-Anwendungen teuer und kompliziert machte und bisher einer weiten Verbreitung von SGML entgegenstand [Bosa1997]. Während HTML also aufgrund der fehlenden Erweiterbarkeit für komplexere Anwendungen ungeeignet ist, erweist sich SGML wegen seiner hohen Komplexität als im Internet nur begrenzt einsetzbar.
Hier setzt die eXtensible Markup Language (XML) an. Mit dem im Februar 1998 vom WorldWideWeb Consortium (W3C9) als Recommendation (Empfehlung) verabschiedeten Sprachkonzept wird versucht, eine für das Internet geeignete Metasprache zu etablieren, die die Funktionalität von SGML für das WorldWideWeb bietet, allerdings ohne dessen hinderliche Komplexität [W3C2000b].
XML ist eine Teilmenge von SGML und wie bei SGML handelt es sich um eine Metasprache. Um die Komplexität zu reduzieren, wurden alle für das Internet als überflüssig angesehenen SGML-Eigenschaften sowie eine Vielzahl als zu kompliziert erachteter und zu selten genutzter Features nicht in XML übernommen. Trotz der Reduzierungen ist XML aufwärtskompatibel zu SGML und wird daher gelegentlich auch ,,SGML lite`` genannt [Mach1997]. Die seit vielen Jahren bewährten grundsätzlichen Ideen von SGML blieben jedoch erhalten, so dass viele Entwickler auf XML trotz seiner erst kurzen Geschichte vertrauen.
XML basiert genau wie SGML auf der Idee des strukturierten Auszeichnens von Daten. Da HTML eine SGML-Anwendung ist, unterscheiden sich XML-Dokumente auf den ersten Blick nicht wesentlich von HTML-Dokumenten. Auch XML-Dokumente bestehen aus durch Tags ausgezeichneten Inhalten. Während die Anzahl und Benennung der Tags für HTML aber vorgegeben ist, können für XML-Dokumente beliebig viele und frei (,,semantisch``) benannte Tags verwendet werden. Somit besteht der wesentliche Unterschied darin, dass bei XML die Auszeichner Informationen über den Inhalt enthalten können und die Verschachtelung der Tags ineinander die Struktur der Daten abbilden kann.
XML unterscheidet sich in den folgenden drei Punkten grundsätzlich von HTML [Bosa1997]:
<?xml version="1.0"?> <!DOCTYPE article SYSTEM "article.dtd"> <article changed="1997/03/10"> <title>XML, Java and the future of the Web</title> <author>Jon Bosak</author> <chapter number="1"> <title>Introduction</title> <paragraph> The extraordinary growth of ... </paragraph> <!-- ... --> </chapter> <newpage/> <!-- ... --> </article>Quellcode 3.1: Ein erstes XML-Beispiel
XML-Dokumente beginnen mit einem Prolog, der allerdings auch leer sein kann, da alle seine Elemente optional sind. Normalerweise befindet sich dort wenigstens die XML-Deklaration mit der Version des XML-Standards, nach der das Dokument erstellt wurde. Allgemein werden processing instructions wie diese, also Anweisungen für Programme, die XML-Dokumente verarbeiten, zwischen <? und ?> gestellt:
<?xml version="1.0"?>
Außerdem kann im Prolog eine Dokumenttyp-Definition referenziert werden:
<!DOCTYPE article SYSTEM "article.dtd">
XML-Dokumente dürfen an fast allen Stellen Kommentare enthalten. Nur innerhalb von Deklarationen, Tags und anderen Kommentaren sind sie nicht erlaubt, sie können also nicht geschachtelt werden. Ein Kommentar beginnt mit der Zeichenfolge <!- und endelt mit ->.
Elemente gliedern ein XML-Dokument logisch bzw. geben ihm seine Struktur. Sie werden von den Auszeichnungen (Tags) des XML-Dokuments gebildet. Jedes Element beginnt mit einem Start-Tag und endet mit dem gleichnamigen Ende-Tag. Der eingeschlossene Inhalt ist der Inhalt des Elements, der Zeichendaten, wiederum Elemente oder eine Mischung von Zeichendaten und Elementen (mixed content) enthalten kann. Durch die Schachtelung von Elementen entsteht die Struktur des XML-Dokuments. Daneben kann es auch leere Elemente geben, die durch ein einzelnes ,,empty element tag`` abgekürzt werden können. Beispielsweise ist <emptyTag></emptyTag> äquivalent zu <emptyTag/>.
Neben dem eigentlichen Inhalt können Elemente auch Attribute enthalten. Die Attribute werden im Start-Tag mit angegeben und in der Form name="wert" angegeben. Im Beispiel besitzt das Element article das Attribut changed und spezifiziert das letzte Änderungsdatum des Artikels.
Attribute können nicht wie Elemente geschachtelt werden, sie enthalten immer nur ,,flachen`` Text. Diesen flachen Text könnte man natürlich auch als weiteres Sub-Element angeben. In der Tat ist es nicht immer eindeutig zu entscheiden, ob gewisse Werte als Attribute oder besser als eigenständige Elemente in XML abgebildet werden.
Mit den bisher vorgestellten Möglichkeiten ist XML nicht viel mehr als ,,strukturiertes ASCII``. Angesichts des Ziels, jede nur mögliche Art von Dokument repräsentieren zu können, ist das nur natürlich.
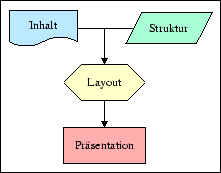
Das Grundkonzept von XML ist die konsequente Trennung von Inhalt, Struktur und Layout von Dokumenten (siehe Abbildung 3.2). Bisher wurde nur über das eigentliche XML-Dokument (den Inhalt) gesprochen. Die genaue Struktur der Daten legt eine Dokumenttyp-Definition fest, die Präsentation des Inhalts erfolgt mit Hilfe eines Stylesheets. Die folgenden Abschnitte beschreiben dieses Konzept, das XML seine Mächtigkeit verleiht.
Dokumenttyp-Definitionen beinhalten die Grammatik, nach der ein XML-Dokument aufgebaut werden kann. D.h. sie geben Auskunft darüber, welche logischen Elemente (bzw. Tags) ein bestimmter Dokumenttyp enthalten darf, welche vorhanden sein müssen und wie sie kombiniert werden dürfen.
Ein Programm (meistens ein XML-Parser) erhält durch die Existenz einer Dokumenttyp-Definition die Möglichkeit, die eingelesenen Dokumente auf die Einhaltung ihrer DTD zu überprüfen. Dokumente, die ihre DTD einhalten, werden als ,,gültig`` (valid) andernfalls als ,,ungültig`` bezeichnet. Gibt ein Dokument keine DTD an, so kann es weder gültig noch ungültig sein. Der Parser kann es dann nur nach den Grundregeln von XML prüfen und man spricht von einem ,,wohlgeformten`` (well formed) Dokument, sofern es diese Regeln erfüllt.
Die grundlegenden Sprachspezifikationen, die für alle XML-Dokumente gelten müssen, sind im wesentlichen die folgenden Punkte:
Quellcode 3.2 listet den Inhalt der DTD des ersten XML-Beispiels auf.
<!ELEMENT article (title,author,(chapter+,newpage?)*)> <!ATTLIST article changed CDATA #REQUIRED> <!ELEMENT title (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT chapter (title,paragraph+)> <!ATTLIST chapter number CDATA ""> <!ELEMENT newpage EMPTY> <!ELEMENT paragraph (#PCDATA)>Quellcode 3.2: DTD des ersten XML-Beispiel
Mit der Anweisung <!ELEMENT name inhalt> werden Elementtypen deklariert. Als inhalt kann entweder eines der Schlüsselwörter EMPTY (kein Inhalt, ,,empty element tag``) oder ANY (beliebiger Inhalt) oder ein sogenanntes content model (Inhaltsmodell) angegeben werden. Inhaltsmodelle erinnern in ihrem Aufbau an reguläre Ausdrücke. Durch Klammern gruppiert und durch Kommata getrennt werden die Elemente angegeben, die nacheinander als Inhalt des Elements auftreten (A,B,C,D). Darf an beliebiger Stelle Text stehen, so verwendet man #PCDATA10. Es ist möglich, Inhalte der Elemente als optional (A?), als alternativ (A|B), mit mindestens einem Vorkommen (A+) oder beliebig vielen (A*) Wiederholungen vorzugeben.
Zu jedem Element kann eine Attributliste deklariert werden. Zu jedem Attribut muss ein Name und ein Typ angegeben werden. Der Attributtyp für einen einfachen Textwert lautet CDATA. Der Attributtyp Enumerated bezeichnet eine Liste möglicher Werte für das Attribut, die durch senkrechte Striche getrennt werden. Das Verweisen auf Elemente eines Dokuments ist über die Attributtypen ID und IDREF möglich.
Zu jedem Attribut muss schliesslich noch ein Defaultwert angegeben werden. Alternativ existieren die Schlüsselworte #REQUIRED (Wert für das Attribut muss im Dokument immer angeben werden), #IMPLIED (der Parser setzt einen sinnvollen Wert ein) und #FIXED (fest vorgegebener Wert). Dazu ein Beispiel:
<!ATTLIST element optional CDATA #IMPLIED mandatory (a|b|c) #REQUIRED unchangeable CDATA #FIXED "123" default (0|1) "0">
Die Darstellung eines XML-Dokuments erfolgt mit Hilfe einer Formatvorlage, eines Stylesheets. In diesem Stylesheet wird das Layout des Dokuments festgelegt. XML zeichnet sich ja gerade durch die unendliche Menge möglicher Tags aus, so dass in einer Applikation (z.B. einem Webbrowser) unmöglich ein Layout für die Tags festgelegt sein kann, wie dies beispielsweise für HTML der Fall ist. Durch Stylesheets können sowohl die Autoren als auch die Nutzer von Webdokumenten deren Präsentation beeinflussen, ohne dabei auf eine geräte- oder anwendungsunabhängige Weiterverarbeitbarkeit verzichten zu müssen [W3C2000c]. So kann die Verwendung unterschiedlicher Stylesheets zur Anpassung eines Dokuments für verschiedene Zwecke, wie beispielsweise Ausdruck und Bildschirmanzeige, genutzt werden. Auf Stylesheets wird durch entsprechende processing instructions verwiesen, z.B.:
<?xml-stylesheet type="text/xsl" href="mystylesheet.xsl"?>
Das W3C entwickelt derzeit mit der eXtensible Stylesheet Language (XSL) eine eigene Stylesheet Sprache für XML [W3C2000d]. Daneben wird seit 1996 die Entwicklung der Cascading Stylesheets (CSS) weitergeführt, einer Stylesheet Sprache, die sowohl mit XML als auch HTML verwendet werden kann. XSL kann im Gegensatz zu CSS Dokumente transformieren. Z.B. ist es mit XSL möglich, die Reihenfolge von Elementen zu verändern.
XSL gliedert sich in eine bereits standardisierte Transformationssprache XSL Transformations (XSLT) und eine Formatierungssprache, die Formatting Objects (XSL-FO). Beide Sprachen sind XML-Anwendungen, d.h. wieder in XML definiert. Mit den Elementen der Transformationssprache XSLT können Regeln definiert werden, die angeben, wie ein XML-Dokument in ein anderes überführt werden soll. Abschnitt 3.6 beschäftigt sich ausführlicher mit dieser Technik.
Die zweite Hälfte der eXtensible Stylesheet Language ist die Formatierungssprache XSL-FO. Sie stellt ein Vokabular zur Verfügung, mit dem eine Formatierung von Elementen medienunabhängig beschrieben werden kann. Die Semantik der Sprachelemente, die Formatting Objects, ist durch die Spezifikation genau definiert. Dies umfasst beispielsweise die Angabe von Abständen und Schriftarten oder die Festlegung des Seitenlayouts. Im Allgemeinen verwendet ein Stylesheet die XSL-Transformationssprache (XSLT), um ein XML-Dokument in ein neues XML-Dokument umzuwandeln, welches die XSL-Formatierungsobjekte und so Vorgaben hinsichtlich der beabsichigten Präsentation enthält. XSL-FO besitzt zur Zeit noch den Status W3C working draft [W3C2000e].
Ein XML-Dokument ist eine Textdatei, die neben dem Inhalt (den reinen Daten) auch dessen Struktur, oder allgemeiner Metadaten, enthält. Betrachtet man ein XML-Dokument genauer, kann man die innere Struktur als Baum auffassen. Eine Baumstruktur beginnt mit einer Wurzel, die selbst keine Vorgänger besitzt. Aus der Wurzel entspringen beliebig viele Äste, die sich wiederum gabeln können bis zu den Blättern. Zur leichteren Betrachtung fasst man Wurzel, Gabelungen und Blätter als Knoten (Nodes) auf, die Äste sind die Verbindungen zwischen den Knoten.
Das Auffassen der logischen Dokumentstruktur als Baum trifft keinerlei Aussage darüber, wie ein XML-Dokument von einem Programm tatsächlich in konkreten Datenstrukturen repräsentiert wird. Wichtig ist aber im Zusammenhang mit anderen Anwendungen, die XML-Dokumente verarbeiten, dass eine Schnittstelle zur XML-Datenstruktur angeboten wird, welche die logische Abarbeitung des Dokuments als Baum ermöglicht. Eine Vereinbarung über eine solche Baumschnittstelle zu XML-Dokumenten wird Document Object Model (DOM) genannt.
Das Document Object Model des W3C wurde allgemein als ein standardisiertes Datenzugriffsmodell entwickelt. Es ist eine plattform- und sprachunabhängige Schnittstelle, die es Programmen und Skriptsprachen erlaubt, dynamisch auf den Inhalt und die Struktur eines XML- oder HTML-Dokuments zuzugreifen und sie zu verändern [W3C2000f].
Wie schon der Name sagt, ist das DOM ein Objektmodell, das die Baumstruktur des Dokuments in einer Objekthierarchie abbildet. Die Objekte selbst sind keine statischen Datenstrukturen, sondern bieten genau definierte Schnittstellen an, die das Auslesen und Verändern des Objektinhalts und der Objekthierarchie ermöglichen. Die DOM-Spezifikation des W3C hat die Aufgabe, diese Schnittstellen (Interfaces) für die unterschiedlichen Objekttypen plattformunabhängig zu definieren.
Bis auf wenige Ausnahmen stammen alle Interfaces des DOM vom Node-Interface ab. Das Node-Interface repräsentiert einen Baumknoten und bietet Methoden zur Navigation in der Objekthierarchie. Weitere Interfaces, die die Bestandteile eines Dokuments (Element, Attribut, Text) charakterisieren, sind direkt vom Node-Interface abgeleitet. Für jeden Objekttyp ist genau festgelegt, welche anderen Objekttypen die untergeordneten Bestandteile bilden dürfen. Hierdurch ist der Aufbau des Objektmodells bestimmten Regeln unterworfen, die garantieren, dass nur wohlgeformte XML-Dokumente dargestellt werden können.
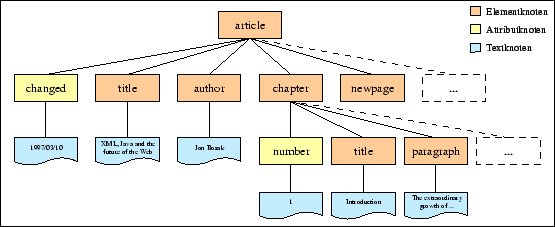
Die aus Quellcode 3.1 resultierende Objekthierarchie stellt Abbildung 3.3 in einem sogenannten Strukturmodell dar. Element-Objekte, die die innerern Knoten der Hierarchie bilden, sind orange dargestellt, Attribut-Objekte gelb und Text-Objekte, die die Blätter des Baums bilden, blau.
Am 13. November 2000 hat das W3C bereits eine Erweiterung des DOM, die Level 2 Specification, als Recommendation - die höchste Stufe eines W3C-Standards - vorgelegt [W3C2000f]. Sie enthält z.B. zusätzliche Schnittstellen für Stylesheets und zum leichteren Traversieren des Objektbaums.
Wie bereits dargestellt, ist XML weit mehr als eine Auszeichnungssprache. Neben der eigentlichen Spezifikation XML 1.0, die definiert, was Tags und Attribute sind, existiert eine wachsende Zahl zusätzlicher Technologien: Eine erweiterte Form der Hyperlinks (XLink) existiert für XML, Verweise auf bestimmte Punkte eines XML-Dokuments sind von ausserhalb möglich (XPointer basierend auf XPath), Namensräume unterstützen die Koexistenz unterschiedlicher XML-Dokumente (XML Namespaces) und genaue Typdefinitionen in XML-Dateien (XML Schema) befinden sich in der Entwicklungsphase. Diese XML-Techniken sind jedoch für den Inhalt dieser Arbeit nicht relevant und werden deshalb nicht genauer erläutert. Einen guten Überblick gibt [Beck2000].
XML ist vom W3C mit dem Ziel entwickelt worden, ein offenes Datenformat für über das Web nutzbare Dokumente zu bieten. Dabei, so zwei der Designziele, solle es sich im Internet auf einfache Weise nutzen lassen und ein breites Spektrum von Anwendungen unterstützen [W3C2000b]. Bislang fehlte eine Möglichkeit, Daten, sei es auf Webseiten oder für unterschiedliche Anwendungen, allgemeinverständlich zu beschreiben. Es fehlte ein universelles Datenformat. Sollte sich die Erfolgsgeschichte von XML weiter fortsetzen, was allgemein erwartet wird, könnte sich die Sprache zum zukünftigen Standard der Datenbeschreibung im Internet entwickeln.
Da XML noch sehr jung ist, befinden sich viele Implementierungen noch in der Entwicklungsphase. Wie bei jeder neuen Technologie besteht auch bei XML Unsicherheit, wie und wofür die Sprache sich wird durchsetzen können. Alle größeren Firmen haben jedoch inzwischen XML-Unterstützung oder XML-Schnittstellen für ihre Produkte angekündigt und leistungsfähige XML-Parser existieren kostenlos von Apache, IBM, Oracle und Sun.
Dass XML ein textbasiertes Format ist, birgt den Nachteil, dass XML-Dateien fast immer mehr Speicherplatz als vergleichbare Binärdateien beanspruchen. Doch Festplattenplatz ist heute nicht mehr teuer. Außerdem können kostenlose Komprimierungsprogramme eingesetzt werden und moderne Kommunikationsprotokolle beherrschen Datenkompression ,,on the fly``. Der große Vorteil eines textbasierten Formats ist, dass es mit einem einfachen Texteditor bearbeitet werden kann - auch wenn XML dafür eigentlich nicht gedacht ist.
Ein häufig unterschätztes Argument für XML ist die Unterstützung internationaler Zeichensätze. Das Internet und die weltweite Kommunikation überwinden Länder- und Sprachgrenzen. Daher unterstützt XML in der Version 1.0 den erweiterten Unicode-Zeichensatz. So ist XML genau wie Java unabhängig von der verwendeten Plattform einsetzbar. Der berühmte Satz des XML-Mitentwicklers Jon Bosak ,,XML gives Java something to do`` [Bosa1997] resultiert aus der Fähigkeit von XML, nicht nur Textdaten, sondern ,,grundsätzlich beliebige, textuell codierbare (also theoretisch alle) Formen von Daten zu speichern. (...) XML könnte also neben der universellen, systemunabhängigen Sprache Java das universelle Datenformat des Web werden.`` [BeMi1998].
Vor dem Hintergrund der oben beschriebenen allgemeinen Vorteile einerseits und der Beschränktheit von HTML andererseits lassen sich vier besonders geeignete Anwendungsfelder für XML identifizieren:
XML besteht aus einigen einfachen Regeln. Die innere Struktur eines XML-Dokuments ist sehr klar und einfach zu verstehen. Aus der simplen Struktur der Dokumente und der Tatsache, dass die Auszeichungen durch die Klammerung (<...>) leicht vom Inhalt zu trennen sind, ergibt sich ein großer Vorteil für die Softwareindustrie.
Zum einen ist die manuelle und maschinelle Erstellung von XML-Dokumenten mit geringem Aufwand zu programmieren. Dokumente können zur Not noch mit einem simplen Texteditor geschrieben werden. Zum anderen hat die einfache Struktur Bedeutung für die Herstellung von Software, die XML-Dokumente verarbeiten kann.
Grundlage für die Verarbeitung von strukturierten semantischen Datenströmen sind sogenannte Parser, die die einzelnen Elemente einer Sprache aus dem Quelltext isolieren, auf syntaktische Korrektheit prüfen und Aktionen auf den Elementen durchführen können. Vereinfacht betrachtet trennt ein XML-Parser die Auszeichnung der Elemente vom Inhalt und stellt die Daten über eine Schnittstelle weiteren Anwendungen zur Verfügung. Die Verarbeitung des Inhalts auf Grund der erkannten Auszeichnungen wird im Allgemeinen erst auf einer höheren Softwareebene durch sogenannte Prozessoren (z.B. bei Stylesheets durch einen XSL-Prozessor) durchgeführt.
Da es in XML nur wenige unterschiedliche Elementtypen gibt, können sowohl Parser als auch Prozessoren in ihrer Grundstruktur einfach, damit robust und kostengünstig, realisiert werden. Zudem verarbeitet ein XML-Parser beliebige auf XML basierende Sprachen (von Neuerungen wie z.B. XML-Schema abgesehen). Bedingt durch die Tatsache, dass sich XML-Parser relativ leicht schreiben lassen und vielfältig einsetzbar sind, existieren heute zahlreiche frei verfügbare XML-Parser für unterschiedliche Sprachen wie Java, C++, Perl und Python.
Für Programmierschnittstellen (Applicaton Programming Interface, kurz API) von XML-Parsern existieren zwei Standards: DOM und SAX. Ein Parser, der die DOM-API implementiert, bietet eine Funktion, die das XML-Dokument komplett einliest und im Speicher eine Repräsentation des Dokuments aufbaut. Über die bereits erwähnten Interfaces des DOM lässt sich der Inhalt der Baumstruktur lesen und verändern.
Da DOM-Parser immer das komplette Dokument einlesen und im Speicher halten, sind sie für sehr große Daten eher ungeeignet. Andererseits ermöglicht das DOM, Dokumente zu manipulieren oder neu zu erzeugen, indem man das Dokument im Speicher bearbeitet und anschließend abspeichert.
Die zweite Programmierschnittstelle ist das SAX, die Simple API for XML. SAX ist ein De-facto-Standard, der nicht vom W3C sondern im Rahmen der XML-DEV Mailingliste entwickelt wurde [Megg2000]. Das XML-Dokument wird dabei sequentiell abgearbeitet und der Parser informiert über Ereignisse, die parsing events. D.h. SAX arbeitet ereignis-gesteuert und man übergibt dem Parser vor dem Start eine Reihe von Callback-Funktionen, die bei jedem Ereignis aufgerufen werden. Zu den parsing events gehören z.B. das Erkennen von Start- oder Ende-Tags oder das Eintreten gewisser Fehlerzustände.
SAX ist schnell und braucht wenig Speicher. Allerdings kann man mit SAX Dokumente nur einlesen, sie können weder manipuliert noch gespeichert werden, da kein Abbild des Dokuments im Speicher erstellt wird.
Allgemein legt die XML 1.0 Spezifikation fest, dass ein Parser keine Korrektur von Fehlern im XML-Dokument vornehmen darf. Im Gegensatz zu einem HTML-Browser, den z.B. fehlende Ende-Tags oder falsch geschachtelte Tags nicht von der Darstellung der Webseite abhalten, muss ein XML-Parser die Bearbeitung des Dokuments sofort mit einer Fehlermeldung beenden, sofern es nicht wohlgeformt ist.
Ein sehr leistungsfähiger XML-Parser, der im Rahmen dieser Arbeit verwendet wird, ist der Apache Xerces-J [Apac2000b]. Er ist in Java implementiert und unterstützt in der Version 1.2.1 sowohl die SAX- als auch die DOM-Schnittstelle (jeweils Level 1 und 2). Eine Überprüfung der XML-Dokumente auf Gültigkeit kann wahlweise erfolgen, d.h. der Parser ist ein validierender Parser. Xerces-J entstand ursprünglich aus dem IBM XML4J XML-Parser und wird inzwischen von der Apache Software Foundation11 weiterentwickelt. Die Quellen des Parsers sind frei verfügbar und dürfen im Rahmen der Apache Software License [Apac2000c] verwendet, verändert und weitergegeben werden.
Die Verwendung eines DOM-Parsers am Beispiel des Apache Xerces-J soll im Folgenden verdeutlicht werden. Nach dem Import der Parser-Klasse org.apache.xerces.parsers.DOMParser und dem Document-Interface org.w3c.dom.Document, das die Wurzel des Dokumentbaums repräsentiert, wird ein XML-Dokument mit wenigen Zeilen Quellcode in ein DOM überführt:
DOMParser parser = new DOMParser();
parser.parse( xmldoc_filename );
Document doc = parser.getDocument();
Standardmäßig überprüft der Xerces-J Dokumente nur auf ihre Wohlgeformtheit. Möchte man die strengere Gültigkeitsprüfung durchführen, muss das entsprechende Feature vor dem Parsen gesetzt werden:
parser.setFeature("http://xml.org/sax/features/validation", true );
Meldungen zu Fehlern, die während des Parsens auftreten, werden normalerweise nicht ausgegeben. Dazu bedarf es eines ErrorHandlers, der dem Parser folgendermaßen mitgeteilt wird:
parser.setErrorHandler( myErrorHandler );
Das Interface org.xml.sax.ErrorHandler vereinbart die Methodenköpfe, die ein ErrorHandler implementieren muss. Sie lauten:
void warning( SAXParseException e ) // warning
void error( SAXParseException e ) // recoverable error
void fatalError( SAXParseException e ) // non-recoverable
Quellcode 3.3 zeigt die genannten Befehle im Zusammenhang. Das Beispiel bekommt den Namen einer XML-Datei als Kommandozeilenparameter und erzeugt das entsprechende DOM des Dokuments mit Hilfe des Xerces-J.
import java.io.IOException; import org.apache.xerces.parsers.DOMParser; import org.w3c.dom.Document; import org.xml.sax.ErrorHandler; import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; /** * Eigener ErrorHandler zur Fehlerausgabe */ class MyErrorHandler implements ErrorHandler { public void warning( SAXParseException e ) { System.err.println("XML PARSER WARNING:\n" + e.getMessage()); } public void error( SAXParseException e ) { System.err.println("XML PARSER ERROR:\n" + e.getMessage()); } public void fatalError( SAXParseException e ) { System.err.println("XML PARSER FATAL ERROR:\n" + e.getMessage()); } } /** * Beispiel zur Verwendung der API des Xerces-DOMParsers */ public class DOMParserExample { public static void main(String[] args) throws IOException, SAXException { DOMParser parser = new DOMParser(); parser.setErrorHandler( new MyErrorHandler() ); parser.setFeature("http://xml.org/sax/features/validation",true); parser.parse( args[0] ); Document doc = parser.getDocument(); // Verarbeitung des Dokuments } }Quellcode 3.3: Verwendung eines DOM-Parsers am Beispiel des Xerces-J
Das XML-Beispiel 3.1 enthält neben dem Inhalt auch die Struktur eines Artikels. Die verwendeten Auszeichnungen beschreiben die Bedeutung der einzelnen Textpassagen (Titel, Autor, Abschnitte, ...). Die zugrundeliegende Sprache, eine XML-Anwendung, ist jedoch frei erfunden und exakt an die eigenen Bedürfnisse angepasst. Kein Texteditor oder Webbrowser kann mit ihrer Semantik etwas anfangen - sie verstehen die Bedeutung der Tags nicht.
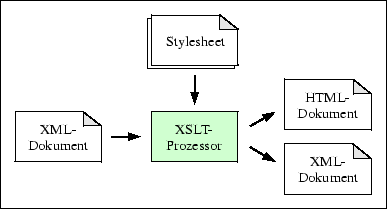
Die Spezifikation der eXtensible Stylesheet Language Transformations (XSLT) definiert Syntax und Semantik einer Sprache, mit der sich XML-Dokumente in eine andere Sprache übersetzen lassen. Dabei handelt es sich bei den Transformationen, die XSLT vornimmt, um die Wandlung eines Dokumentquellbaums (source tree) in einen Ergebnisbaum (result tree). Das Ausgabeformat des Transformationsprozesses kann ein - gewöhnlich auf einer anderen DTD basierendes - XML-Dokument, ein HTML-Dokument oder jedes beliebige Unicode-Textformat sein (siehe Abbildung 3.4).
Um das Beispiel aus Quellcode 3.1 in ein entsprechendes HTML-Dokument umzuwandeln, benötigt man z.B. das Stylesheet aus Quellcode 3.4. Es ist selbst ein wohlgeformtes XML-Dokument, das sich aus Elementen des XSLT Namespace mit dem Präfix ,,xsl`` und anderen (Ergebnis-) Elementen zusammensetzt.
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:template match="/"> <HTML> <HEAD> <TITLE> <xsl:apply-templates select="article" mode="head"/> </TITLE> </HEAD> <BODY> <xsl:apply-templates select="article" mode="body"/> </BODY> </HTML> </xsl:template> <xsl:template match="article" mode="head"> <xsl:value-of select="author"/> <xsl:text>: </xsl:text> <xsl:value-of select="title"/> </xsl:template> <xsl:template match="article" mode="body"> <CENTER> <H1><xsl:value-of select="title"/></H1> <H3>by <xsl:value-of select="author"/></H3> </CENTER> <xsl:apply-templates select="chapter"/> <HR/> Last changed: <xsl:value-of select="@changed"/> </xsl:template> <xsl:template match="chapter"> <P> <H3><xsl:value-of select="title"/></H3> <xsl:apply-templates select="paragraph"/> </P> </xsl:template> <xsl:template match="paragraph"> <xsl:value-of select="."/><BR/> </xsl:template> </xsl:stylesheet>Quellcode 3.4: Stylesheet für das erste XML-Beispiel
Das Wurzelelement xsl:stylesheet legt zu Beginn fest, dass der XSL-Namensraum der von XSLT in der Version 1 ist. Innerhalb dieses Wurzelelements können die folgenden Top-Level-Elemente vorkommen [Behm1999]:
<xsl:import href="..."/> <xsl:include href="..."/> <xsl:strip-space elements="..."/> <xsl:preserve-space elements="..."/> <xsl:output method="..."/> <xsl:key name="..." match="..." use="..."/> <xsl:locale name="...">...</xsl:locale> <xsl:attribute-set name="...">...</xsl:attribute-set> <xsl:variable name="...">...</xsl:variable> <xsl:param name="...">...</xsl:param> <xsl:template name="...">...</xsl:template> <xsl:template match="...">...</xsl:template>
|
Tabelle 3.1: Beispiele für XPath-Angaben
Die Transformation eines XML-Dokuments anhand der Anweisungen eines Stylesheets übernimmt ein XSLT-Prozessor. Ein solcher Prozessor vergleicht die gegebenen Muster mit den Knoten des Quellbaums und generiert den Ergebnisbaum, indem er an den zutreffenden Stellen die entsprechenden templates (Schablonen) anwendet. Dabei werden nur Elemente berücksichtigt, für die Anweisungen im Stylesheet existieren oder eine Standardregel zutrifft (und nicht überdefiniert wurde). Die Standardregeln definieren eine rekursive Abarbeitung aller Elemente beginnend mit der Wurzel, bei der Textelemente und Attributwerte (sofern das Attribut selektiert wird) ausgegeben bzw. procescsing instructions und Kommentare übergangen werden. Im Einzelnen lauten die Regeln:
<xsl:template match="*|/ <xsl:apply-templates/> </xsl:template>
2. Ausgabe von Textelementen und Attributwerten:
<xsl:template match="text()|@*"> <xsl:value-of select="."/> </xsl:template>
3. Keine Verarbeitung von processing instructions und Kommentaren:
<xsl:template match="processing-instruction()|comment()"/>
XSLT bietet weit mehr Möglichkeiten, als am Beispiel gezeigt werden konnte. Die XPath-Spezifikation bietet weitere Funktionen zur Selektion von Knoten und es gibt die Möglichkeit eigene Funktionen zu integrieren. Das Erzeugen von Knoten, die Numerierung (xsl:number-Tag) und die bedingte Verarbeitung (xsl:if und xsl:choose) sind mit XSLT ebenso möglich wie Sortieren und die Übergabe von Parametern an Template-Regeln [Behm1999].
XSLT-Prozessoren sind für die meisten Plattformen frei aus dem Internet zu beziehen. Auch die Apache Software Foundation hat unter dem Namen Xalan einen XSLT-Prozessor entwickelt. Xalan-Java 1.2.1 arbeitet standardmäßig mit dem Apache Xerces-J zusammen, kann aber mit jedem anderen XML-Parser eingesetzt werden, der DOM Level 2 und SAX Level 1 konform ist.
Die Verwendung des Xalan-Java XSLT-Prozessors soll an einem Beispiel verdeutlicht werden.
Das Stylesheet aus Quellcode 3.4 enthielt bereits alle Anweisungen, die nötig sind, um das XML-Beispiel aus Quellcode 3.1 zur Präsentation in einem Webbrowser in eine HTML-Datei umzuwandeln. Die Implementation einer einfachen Transformationsklasse, die die Xalan-API verwendet, zeigt nun Quellcode 3.5. Startet man die Klasse mit dem XML-Dokument und dem Stylesheet als Kommandozeilenparameter, erhält man als Ausgabe Quellcode 3.6. Die Darstellung der HTML-Ausgabe im Webbrowser zeigt abschließend Abbildung 3.5.
import org.apache.xalan.xslt.XSLTProcessorFactory; import org.apache.xalan.xslt.XSLTProcessor; import org.apache.xalan.xslt.XSLTInputSource; import org.apache.xalan.xslt.XSLTResultTarget; /** * Beispielklasse zur Demonstration der API des Xalan-XSLT-Prozessors. * Aufruf: java SimpleTransform document.xml stylesheet.xsl */ public class SimpleTransform { public static void main(String[] args) throws java.io.IOException, java.net.MalformedURLException, org.xml.sax.SAXException { // erzeuge einen XSLT-Prozessor XSLTProcessor processor = XSLTProcessorFactory.getProcessor(); // transformiere XML-Dokument args1 anhand der XSLT-Regeln aus // args2 und schreibe das Ergebnis auf die Standardausgabe processor.process( new XSLTInputSource(args[0]), new XSLTInputSource(args[1]), new XSLTResultTarget(System.out) ); } }Quellcode 3.5: Verwendung eines XSLT-Prozessors am Beispiel des Xalan-Java
<HTML> <HEAD> <TITLE>Jon Bosak: XML, Java and the future of the Web</TITLE> </HEAD> <BODY> <CENTER> <H1>XML, Java and the future of the Web</H1> <H3>by Jon Bosak</H3> </CENTER> <P> <H3>Introduction</H3> The extraordinary growth of ...<BR> </P> <HR> Last changed: 1997/03/10 </BODY> </HTML>Quellcode 3.6: Ausgabe des XSLT-Prozessors für das erste XML-Beispiel
Ein Blick zurück an den Anfang des Kapitels: Das Ziel war die Entwicklung eines textbasierten Dateiformats, das als Schnittstelle zwischen Eingabedaten und Visualisierungsmodul, d.h. der Erzeugung der Flash-Filme, existieren sollte. XML ist ein Standard, der alle Mittel bereitstellt, um ein solches Format exakt zu spezifizieren. Frei verfügbare Software ist in der Lage, beliebige auf XML basierende Sprachen zu verarbeiten, und kann verwendet werden, um Dokumente einzulesen, ihre Struktur und ihren Inhalt zu manipulieren und wieder auszugeben. Die Transformation von einer XML-Sprache in eine andere bzw. in ein Nicht-XML-Format ist ebenfalls standardisiert und wird von Softwarepaketen unterstützt. So ist es also prinzipiell möglich, beliebige auf XML basierende Dateiformate mit den XML-Techniken in das eigene Schnittstellenformat zu konvertierern und für den Visualisierungsprozess zur Verfügung zu stellen.
Einen auf XML abgestimmten Entwurf des Visualisierungsprozesses zeigt Abbildung 3.6 (vgl. Abbildung 3.1).
Das fehlende Modul im vorliegenden Entwurf ist nun noch der Flash-Generator. Wie schon in Abschnitt 2.5 beschrieben, erfordert er recht aufwendige Implementierungsarbeit, um in der Lage zu sein, textbasierte Daten mit Hilfe des Macromedia SWF-SDK in das bitcodierte Flash-Dateiformat zu überführen.
An diesem Punkt der Entwurfsphase stellte sich durch Recherche im Internet heraus, dass bereits eine Applikation existiert, die exakt die genannten eigenen Ideen umsetzt: Saxess Wave, eine in Java geschriebene Applikation der Firma Saxess Software Design aus Köln [Saxe2000].
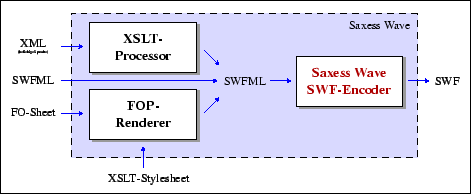
Im ersten Schritt konvertiert Saxess Wave XML-Dokumente mit Hilfe von XSLT in ein ebenfalls auf XML basierendes Format namens SWFML (Shockwave Flash Markup Language), das das binäre Flash-Dateiformat abbildet. Als zweiten und entscheidenden Schritt erzeugt Saxess Wave aus den SWFML-Daten einen Flash-Film. Interessant ist dabei, dass Saxess Wave ohne das Macromedia SWF-SDK arbeitet, sondern die Erzeugung des binären Flash-Dateiformates komplett in eigenen Java-Klassen abwickelt.
Zusätzlich bietet Saxess Wave unter Zuhilfenahme des Apache FOP-Renderers an, XSL-Stylesheets, die Anweisungen der XSL Formatting Objects (XSL-FO) enthalten, nach SWFML zu konvertieren (zu rendern). Die Möglichkeit, über eine Schnittstelle aus den medienunabhängigen Formatierungsangaben der FO-Elemente Flash-Filme zu erzeugen, soll aber hier nicht weiter berücksichtigt werden, da XSL-FO noch nicht den Status eines Standards erreicht hat.
Den Datenfluss von Saxess Wave veranschaulicht Abbildung 3.7.
Saxess Wave - der Flash-Generator? Bei einer genaueren Untersuchung wurde deutlich, dass Saxess Wave für einen ersten Ansatz als Visualisierungsmodul gut geeignet ist, einige bedeutende Fähigkeiten von Flash (z.B. ActionScript) jedoch in der vorliegenden Version 0.5 nicht unterstützt. Saxess Wave 1.0 befindet sich laut Internet-Homepage in der Entwicklung und soll die volle Flash-Unterstützung enthalten. Es wird jedoch auch angekündigt, dass die Software dann nicht mehr als kostenlose Evaluationsversion sondern als Shareware zur Verfügung stehen wird [Saxe2000].
Trotz seiner Einschränkungen soll die Verwendung von Saxess Wave 0.5 vorgestellt werden, da seine Fähigkeiten zur Erzeugung von einfachen nicht-interaktiven Flash-Filmen ausreichen. Im Rahmen dieser Diplomarbeit wird es als Flash-Generator verwendet. Eine nachfolgende Diplomarbeit meines Kommilitonen Ralf Kunze, ebenfalls bei Herrn Prof. Dr. Vornberger, hat die Entwicklung eines umfangreicheren Flash-Generators als Aufgabenstellung, der auf Basis des SWF-SDK den kompletten Funktionsumfang (Interaktivität, Bitmapgrafiken u.a.) bieten wird.
Das in XML formulierte Schnittstellenformat SWFML von Saxess Wave deckt die grundlegenden SWF-Tags ab. Außerdem formuliert es in der zugrunde liegenden DTD einige komplexere Grafikformen, wie z.B. Kreis, Rechteck und Polygon, die auch vom High Level Manager des SWF-SDK (vgl. Abschnitt 2.4) angeboten werden. Generell entspricht der Umfang der mit Saxess Wave zur Verfügung stehenden Grafik-Elemente eher der Flash Version 3, die Handhabung von Texten und Schriften ist jedoch vorbildlich. Das originale Macromedia SWF-SDK stellt für das Einbinden von Texten in Flash-Filme lediglich eine Klasse bereit, mit deren Hilfe die Umrisse der Buchstaben angegeben werden können - Unterstützung zum Auslesen der Umrisse aus lokal vorliegenden Schriftdateien existiert nicht. Saxess Wave hat den Vorteil, dass es in Java implementiert ist und die Java2D-API für diese Aufgabe nutzen kann. So ist bei Saxess Wave in einer SWFML-Datei lediglich die Schriftart, die Schriftgröße und der Text anzugeben und Java2D erstellt die Repräsentation des Textes durch Vektorgrafikobjekte.
Negativ zu erwähnen ist, dass Saxess Wave noch kaum ActionScript, keine Einbindung von Bitmap-Grafiken, keine Verlauffüllungen und keinen Sound unterstützt. So bereitet der Beispiel-Flash-Film, der in Abschnitt 2.4 mit dem High Level Manager des SWF-SDK erzeugt wurde, Saxess Wave bis auf die erwähnten Verlauffüllungen keine Schwierigkeiten und kann dank der SWFML-Schnittstelle ohne Programmierung erstellt werden. Quellcode 3.7 enthält die Formulierung des Beispiels in SWFML.
Das Wurzelelement einer SWFML-Datei heißt SWF und definiert globale Eigenschaften des Flash-Films: Breite (w) und Höhe (h) des Films, Hintergrundfarbe (color) und Framerate (rate), d.h. Anzahl der angezeigten Bilder pro Sekunde. Farbangaben erfolgen in hexadezimaler Notation in der Form "AARRGGBB" oder dezimal in der Form "(a,r,g,b)". Koordinaten bzw. Breiten- und Höhenangaben erfolgen nicht wie beim SWF-SDK in Twips, der Größeneinheit von Flash, die 1/20 Pixel entspricht, sondern in regulären Pixeln. Dadurch ist mit Saxess Wave eine Genauigkeit wie beim SWF-SDK nicht zu erreichen, ein weiterer Nachteil insbesondere beim Zeichnen von feinen Linien.
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE SWF SYSTEM "swf.dtd"> <SWF w="300" h="300" color="FFFFFFFF" rate="3"> <rect ID="rect1" x="0" y="0" w="100" h="100" color="FFFF0000" lc="FF000000" lw="1"/> <rect ID="rect2" x="50" y="50" w="100" h="100" color="FF0000FF" lc="FF000000" lw="1"/> <rect ID="rect3" x="100" y="100" w="100" h="100" color="FFFFFF00" lc="FF000000" lw="1"/> <PlaceObject ID="rect1" depth="1"/> <PlaceObject ID="rect2" depth="2"/> <PlaceObject ID="rect3" depth="3"/> <ShowFrame/> <RemoveObject ID="rect3" depth="3"/> <PlaceObject ID="rect3" depth="3"> <Matrix angle="30.0" tx="95.1" ty="-54.9"/> </PlaceObject> <ShowFrame/> <RemoveObject ID="rect3" depth="3"/> <PlaceObject ID="rect3" depth="3"> <Matrix angle="60.0" tx="204.9" ty="-54.9"/> </PlaceObject> <ShowFrame/> </SWF>Quellcode 3.7: SWFML-Quelle des Beispiel-Films
Alle möglichen Kindelemente des Wurzelelements SWF sollen nicht diskutiert werden, denn sie können der SWFML-DTD entnommen werden. Im Beispiel erfolgt zuerst durch rect-Elemente die Definition der drei Rechtecke mit ihrer Größe, Füllfarbe (color), Linienfarbe (lc) und Liniendicke (lw). Jedes Element bekommt eine eindeutige ID zugewiesen, die für die Referenzierung mit PlaceObject und RemoveObject notwendig ist. PlaceObject kann ein Matrix-Tag enthalten, das eine Verschiebung, Drehung oder Verzerrung der aktuellen Instanz eines bereits definierten Grafikobjekts erlaubt. Dabei erfolgt eine Drehung nicht wie beim SWF-SDK um den Mittelpunkt des Rechtecks, sondern immer um den Ursprung des Koordinatensystems, also um die linke obere Ecke des Films. Daraus resultiert die ebenfalls im Matrix-Tag angegebene Verschiebung des Grafikobjekts an seinen angestammten Platz. Mit einem ShowFrame wird der bis dahin definierte Inhalt eines Frames auf dem Bildschirm angezeigt.
Die ,,Übersetzung`` der SWFML-Quelle in einen Flash-Film erfolgt mit dem Kommando:
java com.saxess.visweb.swfio.Driver in.swfml out.swf
Vergleicht man abschließend die Dateigrößen der beiden fertigen Flash-Filme für dieses noch recht simple Beispiel (beide ohne Verlauffüllungen), so ist die Größe und die innere Tag-Struktur der Dateien identisch. Saxess Wave scheint auch ohne die Verwendung des offiziellen Macromedia SWF-SDK platzsparende Flash-Filme zu produzieren.