![]()
![]()
![]()
Da es sehr zeitaufwendig ist, die Aggregation jedesmal neu zu berechnen, empfiehlt es sich, sie zu materialisieren, d.h. die vorberechneten Aggregate verschiedener Detaillierungsgrade in einer Relation abzulegen. Es folgen einige SQL-Statements, welche die linke Tabelle von Abbildung 16.6 erzeugen. Mit dem null-Wert wird markiert, daß entlang dieser Dimension die Werte aggregiert wurden.
create table Handy2DCube (Hersteller varchar(20),Jahr integer,Anzahl integer); insert into Handy2DCube (select p.Hersteller, z.Jahr, sum(v.Anzahl) from Verkäufe v, Produkte p, Zeit z where v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy' and v.VerkDatum = z.Datum group by z.Jahr, p.Hersteller) union (select p.Hersteller, to_number(null), sum(v.Anzahl) from Verkäufe v, Produkte p where v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy' group by p.Hersteller) union (select null, z.Jahr, sum(v.Anzahl) from Verkäufe v, Produkte p, Zeit z where v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy' and v.VerkDatum = z.Datum group by z.Jahr) union (select null, to_number(null), sum(v.Anzahl) from Verkäufe v, Produkte p where v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy');
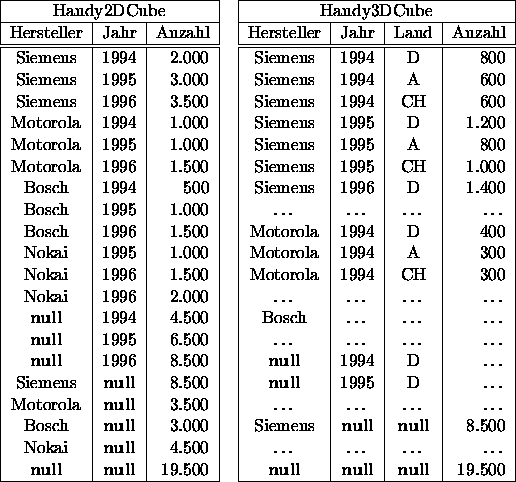
Offenbar ist es recht mühsam, diese Art von Anfragen zu formulieren, da bei n Dimensionen insgesamt 2n Unteranfragen formuliert und mit union verbunden werden müssen. Außerdem sind solche Anfragen extrem zeitaufwendig auszuwerten, da jede Aggregation individuell berechnet wird, obwohl man viele Aggregate aus anderen (noch nicht so stark verdichteten) Aggregaten berechnen könnte.