Datenbanksysteme, die auf dem hierarchischen Datenmodell basieren, haben (nach heutigen Standards) nur eine eingeschränkte Modellierfähigkeit und verlangen vom Anwender Kenntnisse der interne Ebene. Trotzdem sind sie noch sehr verbreitet (z.B. IMS von IBM), da sie sich aus Dateiverwaltungssystemen für die konventionelle Datenverarbeitung entwickelt haben. Die zugrunde liegende Speicherstruktur waren Magnetbänder, welche nur sequentiellen Zugriff erlaubten.
Im Hierarchischen Datenmodell können nur baumartige Beziehungen modelliert werden. Eine Hierarchie besteht aus einem Wurzel-Entity-Typ, dem beliebig viele Entity-Typen unmittelbar untergeordnet sind; jedem dieser Entity-Typen können wiederum Entity-Typen untergeordnet sein usw. Alle Entity-Typen eines Baumes sind verschieden.
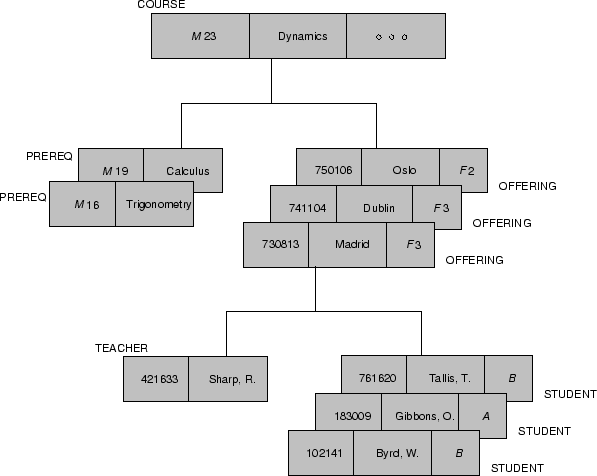
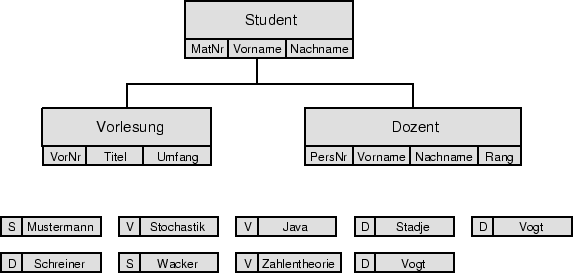
Abbildung 3.1 zeigt ein hierarchisches Schema sowie eine mögliche Ausprägung anhand der bereits bekannten Universitätswelt. Der konstruierte Baum ordnet jedem Studenten alle Vorlesungen zu, die er besucht, sowie alle Professoren, bei denen er geprüft wird. In dem gezeigten Baum ließen sich weitere Teilbäume unterhalb der Vorlesung einhängen, z.B. die Räumlichkeiten, in denen Vorlesungen stattfinden. Obacht: es wird keine Beziehung zwischen den Vorlesungen und Dozenten hergestellt! Die Dozenten sind den Studenten ausschließlich in ihrer Eigenschaft als Prüfer zugeordnet.
Grundsätzlich sind einer Vater-Ausprägung (z.B. Erika Mustermann) für jeden ihrer Sohn-Typen jeweils mehrere Sohnausprägungen zugeordnet (z.B. könnte der Sohn-Typ Vorlesung 5 konkrete Vorlesungen enthalten). Dadurch entsprechen dem Baum auf Typ-Ebene mehrere Bäume auf Entity-Ebene. Diese Entities sind in Preorder-Reihenfolge zu erreichen, d.h. vom Vater zunächst seine Söhne und Enkel und dann dessen Brüder. Dieser Baumdurchlauf ist die einzige Operation auf einer Hierarchie; jedes Datum kann daher nur über den Einstiegspunkt Wurzel und von dort durch Überlesen nichtrelevanter Datensätze gemäß der Preorder-Reihenfolge erreicht werden.
Die typische Operation besteht aus dem Traversieren der Hierarchie unter Berücksichtigung der jeweiligen Vaterschaft, d. h. der Befehl GNP VORLESUNG (gesprochen: GET NEXT VORLESUNG WITHIN PARENT) durchläuft sequentiell ab der aktuellen Position die Preorder-Sequenz solange vorwärts, bis ein dem aktuellen Vater zugeordneter Datensatz vom Typ Vorlesung gefunden wird.
Um zu vermeiden, daß alle Angaben zu den Dozenten mehrfach gespeichert werden, kann eine eigene Hierarchie für die Dozenten angelegt und in diese dann aus dem Studentenbaum heraus verwiesen werden.
Es folgt ein umfangreicheres Beispiel, entnommen dem Buch von C.J. Date. Abbildung 3.2 zeigt das hierarchische Schema, Abbildung 3.3 eine Ausprägung.
Die Query Welche Studenten besuchen den Kurs M23 am 13.08.1973? wird unter Verwendung der DML (Data Manipulation Language) derart formuliert, daß zunächst nach Einstieg über die Wurzel der Zugriff auf den gesuchten Kurs stattfindet und ihn als momentanen Vater fixiert. Von dort werden dann genau solche Records vom Typ Student durchlaufen, welche den soeben fixierten Kursus als Vater haben:
GU COURSE (COURSE#='M23')
OFFERING (DATE='730813');
if gefunden then
begin
GNP STUDENT;
while gefunden do
begin
write (STUDENT.NAME);
GNP STUDENT
end
end;